
The Quantum Computing for Beginners tutorial is written by Martin N. P. Nilsson. The tutorial is split into 3 parts into a web-friendly form. Part 2 and Part 3 can be found below. The original Arxiv article can be found here. All code examples in this series of tutorials is licensed under the MIT license.
The tutorial was inspired by the “Quantum Autumn School” held in October 2023 and organised by ENCCS, Wallenberg Centre of Quantum Technologies (WACQT), and Nordic-Estonian Quantum Computing e-Infrastructure Quest (NordIQuEst). You can find the full recordings and training material of the Quantum Autumn School below.
Do you think you need to know quantum physics to understand how a quantum computer works? Nope, no worries there. You don’t need a deep dive into physics or mathematics, just a bit of familiarity with vectors and matrix multiplication. That’s really it. A good handle on Python programming and a few numpy functions will do the trick, specifically: reshape, kron, matmul, swapaxes, linalg.norm, and random.choice. In fact, Part 3 of this tutorial shows that twelve lines of Python code suffice to define a complete simulator.
The whole point of this article is to give you an informal, brief, hopefully digestible and educational description of how you can easily implement your own quantum computer simulator. It’s not about ‘Yet Another Quantum Computer Simulator’ (YAQCS?), which are a dime a dozen [https://quantiki.org/wiki/list-qc-simulators], but about how to build your own. And, honestly, there’s probably no better way to learn how a quantum computer works!
A Quantum Computer is Like a Rubik’s Cube
To begin with, imagine a quantum computer as a high-dimensional Rubik’s mini-cube (Fig. 1). This cube is formed by a bunch of quantum bits or ‘qubits’, each representing a coordinate axis. So, three qubits define a three-dimensional cube (that’s 2 × 2 × 2), and N qubits define an N -dimensional cube (we’re talking 2 × 2 × . . . × 2 here). The cube consists of N^2 smaller cubes, forming the quantum computer’s exponential ‘workspace’. Each small cube is like a drawer, holding a weight, which is either a real or complex number. But, for simplicity, let’s mostly talk about real numbers here.
In this text, I’ll primarily use computer science terms. However, since physics jargon is pretty common online and in literature, let me briefly describe some basic physics terms and how they map to the concepts I’m using. Physicists call the small cubes eigenstates. The workspace is known as the state vector, comprising a weighted sum of these N^2 eigenstates. Mathematicians would call such a sum a linear combination, while physicists call it a superposition.

The weights are known as amplitudes. A small cube is represented in Dirac or bra-ket notation as |k⟩, where k is the cube’s binary index. For example, cube number 5 is |101⟩, equivalent to the unit vector e_5 in traditional math notation. There are some special symbols too. For instance, |+⟩ typically means the same as (e0 − e1)/\sqrt{2} which can also be written as (\sqrt{1/2}, −\sqrt{1/2}). The set of small cubes \{e_0, e_1, . . . , e_{(2^{N −1})}\} forms a basis for the state vector.
A physical quantum computer with N qubits has a size of O(N), but to simulate it on a classical computer, we need O(N^2) memory. So, we can’t simulate huge quantum computers. But the size we can simulate is enough to understand how a quantum computer works from a programmer’s perspective.
There are three main steps in quantum computing:
- Building up the workspace.
- Performing operations on the workspace.
- Reading from the workspace.
There are some rules and limitations from physical laws, but they’re not too weird. We have an exponentially large workspace, and the cool thing is we can perform certain primitive operations (like matrix multiplications) on the entire memory in constant time on a physical quantum com- puter. Despite the limitations, there are clever combinations of operations that are very useful, even if finding them can be tricky.
In this tutorial, we’ll describe how you can build a quantum computer simulator as a stack machine.
The Quantum Computer as a Stack Machine
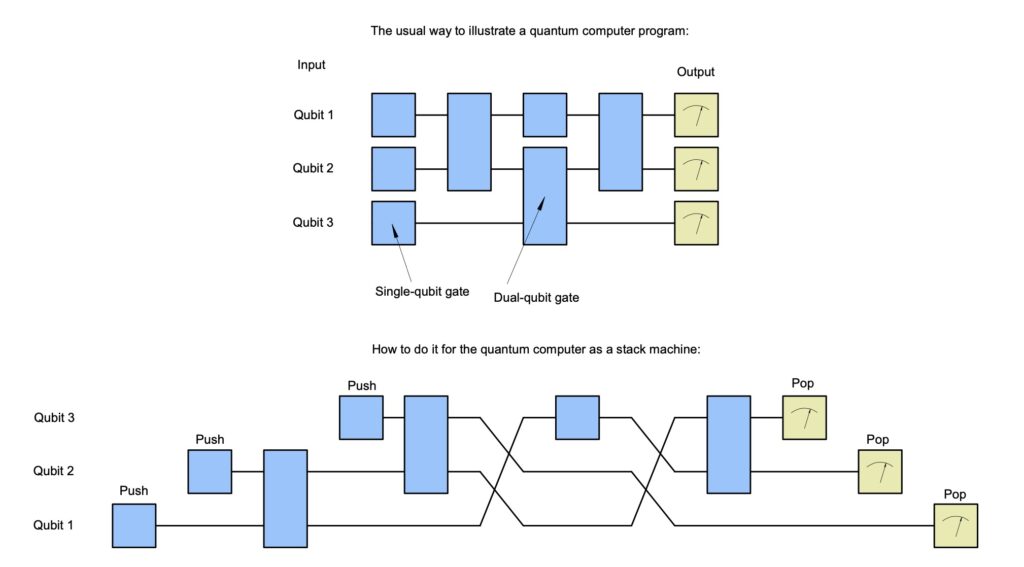
Think of a quantum computer as a stack machine (Fig. 2). For me, this was a real ‘aha!’ moment! The workspace functions like a stack and can be represented as an array that’s built up by pushing qubits onto it. This is done by calculating the Kronecker product \otimes (also known as the tensor product) of the workspace M, represented as a vector with 2^N elements, and the new qubit q, represented as a vector with two elements, so that M \leftarrow M \otimes q. Here’s a little example of how the Kronecker product works:
\begin{aligned}
(a, b, c, d) ⊗ (\alpha, \beta) & = (a · (\alpha, \beta), b · (\alpha, \beta), c · (\alpha, \beta), d · (\alpha, \beta)) \\
& = (a\alpha, a\beta, b\alpha, b\beta, c\alpha, c\beta, d\alpha, d\beta)
\end{aligned}
The difference from a traditional stack is that the whole quantum stack changes when we push a qubit, not just the top. The Kronecker product can be computed using the kron function in numpy. The qubit gets, sort of, ‘woven’ into the entire stack.
A gate operation is performed on the top qubits in the stack, kind of like twisting layers on a Rubik’s cube. Such an operation is simply done with a matrix multiplication, matmul in numpy.
We also need an operation to move a qubit in the stack to the top position (TOS, ‘Top Of Stack’). For the workspace, this means permuting the array’s axes, which we achieve with numpy’s swapaxes procedure.
Finally, we need to pop qubits from the stack and read them off. This is done by calculating the probability that a qubit will be zero or one using numpy’s linalg.norm function, and then randomly drawing a value according to these probabilities. (The remaining stack, i.e., the workspace, can be associated with the conditional probabilities given that the popped qubit had the drawn value. You don’t need to know exactly what this means, but it will become clear how this works in the code later.)
First, we’ll go through the implementation of the four basic instructions push, gate operation, move, and pop in detail. All the instructions can be implemented by first transforming the workspace with numpy’s reshape and then applying a numpy function (kron, matmul, swapaxes, or linalg.norm) to this array. If you reshape the workspace into a vector, you can think of it as a table containing a weight for each small cube. The transformation is a permutation of the array’s indices but never changes the content.
Instruction 1: Push a Qubit onto the Stack
Every time you push a new qubit onto the stack, the size of the workspace doubles. Imagine a ‘fresh’ qubit represented by a weight vector (α, β), where α and β are weights that have to satisfy the condition |\alpha|^2 + |\beta|^2 = 1 . You can think of |α|^2 as the probability that the qubit is zero, and |β|^2as the probability that it’s one. A qubit that’s definitely zero can be represented by the vector (1, 0), while one that’s certainly one is (0, 1). And a qubit that’s equally likely to be zero or one can be represented with (\sqrt{1/2}, \sqrt{1/2}).
To implement this operation, we first reshape the workspace into a (1 × N^2)-matrix (that’s a row vector) and then use numpy’s kron function to expand the memory to the Kronecker product of the workspace and the new qubit’s weight vector.
import numpy as np
def pushQubit(weights):
global workspace
workspace = np.reshape(workspace,(1,-1)) workspace = np.kron(workspace,weights)The parameter (1,-1) in the reshape function means that we’re reshaping the array into a matrix with one row (that’s what the one in (1,-1) is telling us) and as many columns as needed (and that’s what the minus one in (1,-1) is for).
Here comes a code example. We’ll start by creating an empty workspace.
workspace = np.array([[1.]]) # create empty qubit stack pushQubit([1,0])
pushQubit([1,0])
print(workspace)
pushQubit([3/5,4/5]) # push a 2nd qubit print(workspace)
print(workspace)[[1. 0.]]
[[0.6 0.8 0. 0. ]]The only place in the code where we explicitly specify the data type is when we create the quantum stack workspace. An empty quantum stack is represented by a matrix that consists of exactly one row and one column containing the number one.
Instruction 2: Perform a Gate Operation
Now, let’s do operations on the qubits. These are called gates and are carried out through matrix multiplications that involve the whole workspace. You can’t manipulate individual small cubes; you have to manipulate the entire workspace at once. It’s a bit like how you can’t just turn a single cube in a Rubik’s Cube; you have to turn an entire layer.
Gate operations never remove or add any qubits. A gate applied to M qubits corresponds to a matrix multiplication of the entire workspace with a (2^M × 2^M )-matrix U . We don’t really need to worry about the formal requirements for the matrix U, as almost always only a handful of predefined matrices are used. But it’s good to know that the matrix U must be unitary, which means that the inverse U^{-1} is the same as the transposed and complex-conjugated matrix U^{H}. Other than this, the matrix can look any way you like. Of course, it can be tricky to practically realize irregular matrices on a physical quantum computer.
Usually, gates are used on one to three qubits (1 ≤ M ≤ 3). It can be shown that all gates with M > 2 can be expressed as sequences of gates with M ≤ 2.
We implement the gate operation by first reshaping the workspace into a (2^{N-M} × 2^M)-matrix, which we then multiply with the gate matrix, having dimensions 2^M × 2^M.
Example of applyGate: A common gate is the X-gate:
def applyGate(gate):
global workspace
workspace = np.reshape(workspace,(-1,gate.shape[0]))
np.matmul(workspace,gate.T,out=workspace)Example of applyGate: A common gate is the X-gate:
X_gate = np.array([[0, 1], # Pauli X gate
[1, 0]]) # = NOT gateThis gate switches the probabilities for a qubit being zero or one, which you can see by performing the multiplication
\begin{pmatrix}
0 & 1 \\
1 & 0
\end{pmatrix}
\begin{pmatrix}
a \\
b
\end{pmatrix}
=
\begin{pmatrix}
b \\
a
\end{pmatrix}.That’s why the X-gate is also called a NOT gate. Here’s what a run looks like on a qubit that is zero, i.e., represented by the weights (1, 0):
np.matmul(X_gate,[1,0])array([0, 1])Or as a sample run using our new instructions pushQubit and applyGate:
workspace = np.array([[1.]]) # reset workspace
pushQubit([1,0])
print("input",workspace)
applyGate(X_gate) # = NOT
print("output",workspace)input [[1. 0.]]
output [[0. 1.]]The Hadamard gate is another common and important gate:
H_gate = np.array([[1, 1], # Hadamard gate
[1,-1]]) * np.sqrt(1/2)When applied to a qubit that is zero, represented by (1, 0), it changes the qubit so that it has an equal probability of being zero or one. You can see this through the following matrix multiplication:
\frac{1}{\sqrt{2}}
\begin{pmatrix}
1 & 1 \\
1 & -1
\end{pmatrix}
\begin{pmatrix}
1 \\
0
\end{pmatrix}
=
\frac{1}{\sqrt{2}}
\begin{pmatrix}
1 \\
1
\end{pmatrix}
Some code examples:
workspace = np.array([[1.]])
pushQubit([1,0])
print("input",workspace)
applyGate(H_gate)
print("output",workspace)input [[1. 0.]]
output [[0.70710678 0.70710678]]If we use complex weights, for example when we’re using T-gates, we need to initialise workspace with a complex data type:
T_gate = np.array([[1, 0],
[0,np.exp(np.pi/-4j)]])
workspace = np.array([[1.+0j]]) # set complex workspace pushQubit([.6,.8])
print("input",workspace)
applyGate(T_gate)
print("output",workspace)input [[0.6+0.j 0.8+0.j]]
output [[0.6 +0.j 0.56568542+0.56568542j]]In this article, however, most examples use only real numbers.
A gate that can be applied to two qubits is the SWAP gate:
SWAP_gate = np.array([[1, 0, 0, 0], # Swap gate [0, 0, 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 1]])It changes the qubit order:
workspace = np.array([[1.]])
pushQubit([1,0]) # qubit 1
pushQubit([0.6,0.8]) # qubit 2
print(workspace)
applyGate(SWAP_gate)
print(workspace)[[0.6 0.8 0. 0. ]]
[[0.6 0. 0.8 0. ]]After a bit of thought, you’ll see that the first row in the output corresponds to qubit 1 ⊗ qubit 2, while the second one corresponds to qubit 2 ⊗qubit 1.
Here’s a list of most of the common gates:
X_gate = np.array([[0, 1], # Pauli X gate
[1, 0]]) # = NOT gate
Y_gate = np.array([[ 0,-1j], # Pauli Y gate
[1j, 0]]) # = SHZHZS
Z_gate = np.array([[1, 0], # Pauli Z gate
[0,-1]]) # = P(pi) = S^2
# = HXH
H_gate = np.array([[1, 1], # Hadamard gate
[1,-1]]) * np.sqrt(1/2)
S_gate = np.array([[1, 0], # Phase gate
[0,1j]]) # = P(pi/2) = T^2
T_gate = np.array([[1, 0], # = P(pi/4)
[0,np.exp(np.pi/-4j)]])
Tinv_gate = np.array([[1, 0], # = P(-pi/4)
[0,np.exp(np.pi/4j)]]) # = T^-1
def P_gate(phi): # Phase shift gate
return np.array([[1, 0],
[0,np.exp(phi*1j)]])
def Rx_gate(theta): # Y rotation gate
return np.array([[np.cos(theta/2),-1j*np.sin(theta/2)],
[-1j*np.sin(theta/2),np.cos(theta/2)]])
def Ry_gate(theta): # Y rotation gate return
np.array([[np.cos(theta/2),-np.sin(theta/2)],
[np.sin(theta/2), np.cos(theta/2)]])
def Rz_gate(theta): # Z rotation gate
return np.array([[np.exp(-1j*theta/2), 0],
[ 0,np.exp(1j*theta/2]])
CNOT_gate = np.array([[1, 0, 0, 0], # Ctled NOT gate
[0, 1, 0, 0], #=XORgate
[0, 0, 0, 1],
[0, 0, 1, 0]])
CZ_gate = np.array([[1, 0, 0, 0], # Ctled Z gate
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0,-1]])
SWAP_gate = np.array([[1, 0, 0, 0], # Swap gate
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 1]])
TOFF_gate = np.array([[1, 0, 0, 0, 0, 0, 0, 0], # Toffoli gate
[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 1, 0]])It’s the gate operations that are applied to more than one qubit (M ≥ 2) that introduce entanglement and enable the quantum computer to perform interesting calculations.
Instruction 3: Move a Qubit to the Top of the Stack
Since we only apply gates to the top qubits in the stack, we need an instruction that moves the Kth qubit from the top to TOS (Top Of Stack), and shifts the other K − 1 qubits down a step. This can be achieved with numpy’s swapaxes function, but first, we reshape the workspace so that the second to last index corresponds to the qubit we want to move to TOS.
def tosQubit(k):
global workspace
if k > 1: # if non-trivial
workspace = np.reshape(workspace,(-1,2,2**(k-1)))
workspace = np.swapaxes(workspace,-2,-1)Example of tosQubit : In the previous example, we used a SWAP gate to switch the positions of two qubits in the stack. Now, we can do it with the tosQubit instruction instead:
workspace = np.array([[1.]])
pushQubit([1,0])
pushQubit([0.6,0.8])
print(workspace)
tosQubit(2)
print(workspace)[[0.6 0.8 0. 0. ]]
[[[0.6 0. ]
[0.8 0. ]]]In the second line of the output, the reshaping remains after tosQubit. If we don’t want this and prefer it in the form of a row vector, we can instead write
print(np.reshape(workspace,(1,-1)))[[0.6 0. 0.8 0. ]]Instruction 4: Measure a Qubit
When we measure a qubit, it’s automatically popped from the stack. Physicists call this collapse. We don’t get a weight as a result, but rather either zero or one, depending on the combined proba- bilities of the small cubes that correspond to zero or one. To know the probability of a 0, we need to sum up the probabilities for all the small cubes where the corresponding coordinate is a 0. If α is the weight in the small cube, then |α|^2 is the probability for that cube. We can calculate the total probability using numpy’s linalg.norm function.
Then, we draw either a one or a zero accord- ing to these probabilities. That’s the final value of the popped qubit, and this drawing is what’s called measurement. After the measurement, we discard all the small cubes that don’t match the measurement result. That’s the actual collapse. The workspace will then shrink to half its size. We have simply popped away one dimension of the cube. We also normalize the remaining weights so that the total probability becomes one.
def probQubit():
global workspace
workspace = np.reshape(workspace,(-1,2))
return np.linalg.norm(workspace,axis=0)**2
def measureQubit():
global workspace
prob = probQubit()
measurement = np.random.choice(2,p=prob) # select 0 or 1
workspace = (workspace[:,[measurement]]/
np.sqrt(prob[measurement]))
return str(measurement)The function probQubit calculates the probability for the qubit on top of the stack to be zero or one by computing the sum of squares of the corresponding columns in the workspace. It is called by the function measureQubit, which randomly draws a zero or one according to these probabilities using random.choice. Finally, the corresponding column is extracted and normalized to become the new workspace.
Example of measureQubit : In the next example, we push a qubit that has the value zero with a probability of 0.6^2 = 0.36 and the value one with a probability of 0.8^2 = 0.64. The odds 36 : 64 = 9 : 16 mean that if we run the program 25 times, we’ll get approximately 9 zeros and 16 ones:
workspace = np.array([[1. ]])
for n in range(30):
pushQubit([0.6,0.8])
print(measureQubit(), end="")001010110010111001101111110110To be precise, all possible values for the qubit are calculated, but we can only read off one value for each qubit per run, because as soon as we read it, the representation of the bit collapses to that value.
In a slightly more advanced example with three qubits, we combine two Hadamard gates with a Toffoli gate. This combination computes AND, and to demonstrate this, we generate a truth table:
workspace = np.array([[1.]])
for i in range(16):
pushQubit([1,0]) # push a zero qubit
applyGate(H_gate) # set equal 0 and 1 probability
pushQubit([1,0]) # push a 2nd zero qubit
applyGate(H_gate) # set equal 0 and 1 probability
pushQubit([1,0]) # push a dummy zero qubit
applyGate(TOFF_gate) # compute Q3 = Q1 AND Q2
q3 = measureQubit() # pop qubit 3
q2 = measureQubit() # pop qubit 2
q1 = measureQubit() # pop qubit 1
print(q1+q2+q3,end=",")
000,010,000,100,000,100,111,010,100,010,100,000,000,100,010,010,What’s happening here is that even though the code calculates qubit 3 for all values of qubits 1 and 2 each loop iteration, we still need to rerun the program to get the full table. The big problem with quantum computers isn’t doing calculations; it’s getting the results out!
This is it—a quantum computer isn’t really any more complicated than this. The instructions pushQubit, applyGate, tosQubit, and measureQubit can do everything a quantum computer can do, but of course, they take much (exponentially) more space and time. In the next section, we’ll improve the code and try some more advanced examples.
Some Code Improvements
We can make some improvements to the code to make it easier to use. Most importantly, we want to be able to refer to qubits by names. So, we introduce a name stack, which is a classic stack for the names of the qubits.
Improved pushQubit: For pushQubit, we also normalize the weights inside the procedure so that the user doesn’t have to think about it. We take the opportunity to reset the name stack if we see that the workspace is empty. When we push the qubit, we ensure that the weights are converted to the same type as workspace to prevent kron from using up unnecessary memory.
def pushQubit(name,weights):
global workspace
global namestack
if workspace.shape == (1,1): # if workspace empty
namestack = [] # then reset
namestack.append(name) # push name
weights = weights/np.linalg.norm(weights) # normalize
weights = np.array(weights,dtype=workspace[0,0].dtype)
workspace = np.reshape(workspace,(1,-1)) # to row vector
workspace = np.kron(workspace,weights)Example of pushQubit: A simple example:
workspace = np.array([[1.]]) # create empty qubit stack
pushQubit("Q1",[1,1]) # push a qubit
print(np.reshape(workspace,(1,-1))) # print workspace as vector print(namestack)
pushQubit("Q2",[0,1]) # push a 2nd qubit
print(np.reshape(workspace,(1,-1))) # print workspace as vector print(namestack)[[0.70710678 0.70710678]]
['Q1']
[[0. 0.70710678 0. 0.70710678]]
['Q1', 'Q2']Here, we’ve initialized qubit Q1 with weights [1,1] instead of first initializing with [1,0] and then applying a Hadamard gate. The weights are normalized inside pushQubit, so the result is identical.
Improved tosQubit: For tosQubit, we only need to calculate how many qubits need to be moved, and also rotate the name stack. Negative indices in Python mean counting from the end of the list, so minus one refers to the last element in the list.
def tosQubit(name):
global workspace
global namestack
k = len(namestack)-namestack.index(name) # qubit pos
if k > 1: # if non-trivial
namestack.append(namestack.pop(-k)) # rotate name stack
workspace = np.reshape(workspace,(-1,2,2**(k-1)))
workspace = np.swapaxes(workspace,-2,-1)Example of tosQubit: We continue the previous example:
print(np.reshape(workspace,(1,-1))) # print workspace as vector
print(namestack)
tosQubit("Q1") # swap qubits
print(np.reshape(workspace,(1,-1))) # print workspace as vector print(namestack)[[0. 0.70710678 0. 0.70710678]]
['Q1', 'Q2']
[[0. 0. 0.70710678 0.70710678]]
['Q2', 'Q1']Improved applyGate: We allow the procedure to take the names of the qubits that are to be moved to the top of the stack as arguments, so this move can be built into the gate operation.
def applyGate(gate,*names):
global workspace
for name in names: # move qubits to TOS
tosQubit(name)
workspace = np.reshape(workspace,(-1,gate.shape[0]))
np.matmul(workspace,gate.T,out=workspace)Example of applyGate: Let’s continue with the latest example:
print(np.reshape(workspace,(1,-1))) # print workspace as vector
print(namestack)
applyGate(H_gate,"Q2") # H gate on qubit 2
print(np.reshape(workspace,(1,-1))) # turns a 0 qubit to 1
print(namestack) # with 50% probability[[0. 0. 0.70710678 0.70710678]]
['Q2', 'Q1']
[[ 0.5 -0.5 0.5 -0.5]]
['Q1', 'Q2']Improved measureQubit: There are no major changes needed for measureQubit, other than that we now provide the name of the qubit to be measured as an argument.
def probQubit(name):
global workspace
tosQubit(name)
workspace = np.reshape(workspace,(-1,2))
prob = np.linalg.norm(workspace,axis=0)**2
return prob/prob.sum() # make sure sum is one
def measureQubit(name):
global workspace
global namestack
prob = probQubit(name)
measurement = np.random.choice(2,p=prob)
workspace = (workspace[:,[measurement]]/
np.sqrt(prob[measurement]))
namestack.pop()
return str(measurement)Examples of probQubitand measureQubit: First a simple example:
workspace = np.array([[1.]])
pushQubit("Q1",[1,0])
applyGate(H_gate,"Q1")
print("Q1 probabilities:", probQubit("Q1")) # peek Q1 prob
pushQubit("Q2",[0.6,0.8])
print("Q2 probabilities:", probQubit("Q2")) # peek Q2 prob
print(measureQubit("Q1"), measureQubit("Q2"))Q1 probabilities: [0.5 0.5]
Q2 probabilities: [0.36 0.64]
0 1The function probQubit is impossible in a physical quantum computer because the probabilities collapse as soon as you try to measure them. However, the function is very useful for debugging in a quantum computer simulator.
Here’s a more complex example that demonstrates how a Toffoli gate can be implemented with Hadamard, T, inverse T, and CNOT gates. How it works is quite baffling, but the fact that it works is interesting because it shows that it is possible:
def toffEquiv_gate(q1,q2,q3): # define Toffoli gate
applyGate(H_gate,q3) # using H, T, T*, CNOT
applyGate(CNOT_gate,q2,q3)
applyGate(Tinv_gate,q3)
applyGate(CNOT_gate,q1,q3)
applyGate(T_gate,q3)
applyGate(CNOT_gate,q2,q3)
applyGate(Tinv_gate,q3)
applyGate(CNOT_gate,q1,q3)
applyGate(T_gate,q2)
applyGate(T_gate,q3)
applyGate(H_gate,q3)
applyGate(CNOT_gate,q1,q2)
applyGate(T_gate,q1)
applyGate(Tinv_gate,q2)
applyGate(CNOT_gate,q1,q2)
workspace = np.array([[1.+0j]]) # prep COMPLEX array
for i in range(16): # test function
pushQubit("Q1",[1,1])
pushQubit("Q2",[1,1])
pushQubit("Q3",[1,0])
toffEquiv_gate("Q1","Q2","Q3") # compute Q3 = Q1 AND Q2
print(measureQubit("Q1")+measureQubit("Q2")+
measureQubit("Q3"), end=",")000,010,100,010,010,111,010,010,000,100,100,000,111,000,100,111,It can be shown that at least six CNOT gates are needed to implement the Toffoli gate. Any circuit that can be built with the logical gates AND, OR, and NOT—that is, combinational circuits—can also be built with quantum gates. The finesse of doing it with quantum gates is that you essentially calculate the function for all possible inputs in a single run. The big challenge is how to read out the result. We’ll take a closer look at that in the section on Grover’s search.
Controlled Gates and Recycling of Qubits
As we saw earlier, the CNOT gate plays a significant role in quantum computers. The ‘C’ in ‘CNOT’ stands for ‘Controlled,’ meaning that the gate performs a NOT on the controlled qubit if and only if the control qubit is one; otherwise, the gate does nothing. It’s common for a gate to have multiple control qubits, and then there’s an implicit AND between them, meaning all control qubits must be one for the operation to occur. Examples of this in the list of common gates above include, besides CNOT, ‘Controlled Z’ (CZ) and the Toffoli gate (TOFF).
Controlled gates with many control qubits can always be implemented using gates with only one or two control qubits. Here’s an example showing how a Toffoli gate with three control qubits can be constructed using a regular Toffoli gate with two control qubits:
def TOFF3_gate(q1,q2,q3,q4): # q4 = q4 XOR (q1 AND q2 AND q3)
pushQubit("temp",[1,0]) # push a zero temporary qubit
applyGate(TOFF_gate,q1,q2,"temp") # t = q1 AND q2
applyGate(TOFF_gate,"temp",q3,q4) # q4 = q4
XOR (t AND q3) measureQubit("temp") # pop temp qubit - PROBLEM HERE!This code looks deceptively simple, but there’s a catch. We’ve had to introduce an ‘ancilla qubit,’ temp. So far, so good, but: You must reset ancilla qubits to definitely be either 0 or 1 before they are popped or reused! Otherwise, the qubit’s entanglement with other qubits can create problems similar to ‘dangling pointers’ in classical programming. The standard way to reset an ancilla qubit is to reverse all the operations performed on it, using the inverse gates. For instance, if you’ve applied HT to a qubit, you should perform (HT)^{−1} = T^{−1}H^{−1} = T^{−1}H to reset it. This process is known as ‘uncomputing.’ Since the Toffoli gate is its own inverse, including the sample run, the correct code becomes
def TOFF3_gate(q1,q2,q3,q4):
pushQubit("temp",[1,0]) applyGate(TOFF_gate,q1,q2,"temp")
applyGate(TOFF_gate,"temp",q3,q4)
applyGate(TOFF_gate,q1,q2,"temp") # restore temp
measureQubit("temp") # t is surely zero
workspace = np.array([[1.]]) # test!
for i in range(20): # generate truth table
pushQubit("Q1",[1,1])
pushQubit("Q2",[1,1])
pushQubit("Q3",[1,1])
pushQubit("Q4",[1,0]) # Q4 starts at zero so
TOFF3_gate("Q1","Q2","Q3","Q4") # Q4 = AND of Q1 thru Q3
print("".join([measureQubit(q) for q in
["Q1","Q2","Q3","Q4"]]), end=",")0000,1000,1111,0110,1111,1111,0110,1111,1010,0100,0010,0110,1000,
0000,0100,0110,0000,0100,1100,0110,We can generalize the Toffoli gate to take an arbitrary number of control qubits in the following way:
def TOFFn_gate(ctl,result): # result = result XOR AND(qubits)
n = len(ctl)
if n == 0:
applyGate(X_gate,result)
if n == 1:
applyGate(CNOT_gate,ctl[0],result)
elif n == 2:
applyGate(TOFF_gate,ctl[0],ctl[1],result)
elif n > 2:
k=0
while "temp"+str(k) in namestack:
k=k+1
temp = "temp"+str(k) # generate unique name
pushQubit(temp,[1,0]) # push zero temp qubit
applyGate(TOFF_gate,ctl[0],ctl[1],temp) # apply TOFF
ctl.append(temp) # add temp to controls
TOFFn_gate(ctl[2:],result) # recursion
applyGate(TOFF_gate,ctl[0],ctl[1],temp) # uncompute temp
measureQubit(temp) # pop temp
workspace = np.array([[1]],dtype=np.single) # test!
for i in range(20): # generate truth table
pushQubit("Q1",[1,1])
pushQubit("Q2",[1,1])
pushQubit("Q3",[1,1])
pushQubit("Q4",[1,0]) # Q4 starts at zero, becomes
TOFFn_gate(["Q1","Q2","Q3"],"Q4") # AND of Q1 thru Q3
print("".join([measureQubit(q) for q in
["Q1","Q2","Q3","Q4"]]),end=",")1111,1111,1100,0110,0010,0110,0010,0110,0100,0010,1111,0110,0100,
0000,1100,0110,1111,0000,0100,1010,Such multi-input-controlled gates are very useful. They allow us, for example, to test equality in a straightforward way by performing an AND on the control qubits. A downside is that they use many ancilla qubits (try writing it without them!), and the number of qubits is a critical resource.
Characteristic of multi-input-controlled gates is that their matrix representation is almost an iden- tity matrix, that is, a matrix that is zero everywhere except on the diagonal, where there are ones. They differ only in the lower right corner, in the last two rows and columns. We can take advantage of this for an efficient implementation of controlled gates that avoids using ancilla qubits, like so:
def applyGate(gate,*names):
global workspace
if list(names) != namestack[-len(names):]: # reorder stack
for name in names: # if necessary
tosQubit(name)
workspace = np.reshape(workspace,(-1,2**(len(names))))
subworkspace = workspace[:,-gate.shape[0]:]
np.matmul(subworkspace,gate.T,out=subworkspace)An additional optimization here is to avoid moving qubits if the stack is already in order. Above we have used the number of rows in the gate matrix to determine which qubits are the control qubits. Only a small part of the workspace is involved in the multiplication. Now we can define the Toffoli gates this elegantly:
def TOFF3_gate(q1,q2,q3,q4):
applyGate(X_gate,q1,q2,q3,q4)
def TOFFn_gate(ctl,result):
applyGate(X_gate,*ctl,result)
workspace = np.array([[1]],dtype=np.single)
for i in range(20):
pushQubit("Q1",[1,1])
pushQubit("Q2",[1,1])
pushQubit("Q3",[1,1])
pushQubit("Q4",[1,0])
TOFF3_gate("Q1","Q2","Q3","Q4")
print("".join([measureQubit(q) for q in
["Q1","Q2","Q3","Q4"]]),end="/")
pushQubit("Q1",[1,1])
pushQubit("Q2",[1,1])
pushQubit("Q3",[1,1])
pushQubit("Q4",[1,0])
TOFFn_gate(["Q1","Q2","Q3"],"Q4")
print("".join([measureQubit(q) for q in
["Q1","Q2","Q3","Q4"]]),end=",")0010/1000,0000/1000,0100/0000,0110/0110,0010/1100,0000/0100,1100/
1000,0000/0010,1100/1000,0110/1010,1010/1000,0100/1111,1111/0010,
0000/1000,0100/0100,1000/1010,1111/0000,0010/0010,0010/0000,1100/
0000,In the next chapter, we continue with Grover’s Search.




