One of main tasks for the ENCCS project is to enable Nek5000 to run on LUMI GPU partitions and other Prace Tier-0 heterogeneous systems for large scale simulations. It was announced in the LUMI press conference on October 21, 2020 that the LUMI partition will be equipped by the AMD Instinct GPUs with peak performance of 550 PFLOPs. Furthermore, it is written in a recent LUMI blog:
" If you can currently build your OpenACC programs with the GNU compiler, you should be able to use OpenACC on LUMI. As an alternative to OpenACC, LUMI will support programs using OpenMP directives to offload code to the GPUs. OpenMP offloading has better support from the system vendor, meaning it may be worth considering porting your OpenACC code to OpenMP."
Nek5000 has been ported to GPU using OpenACC [1]. However, with this advice we rewrote code using OpenMP GPU offloading [2]. Fortunately, the map between OpenACC and OpenMP GPU offloading is rather straightforward and almost one-by-one. As a example, for the most time-consuming matrix-matrix multiplications in the Nek5000, the OpenACC directive COLLAPSE instruct is used to collapse the quadruply nested loop into a single loop
!$ACC PARALLEL LOOP COLLAPSE(4)The corresponding OpenMP GPU offloading directive is
!$OMP TARGET TEAMS DISTRIBUTE PARALLEL DO COLLAPSE(4)Though we encountered many compilation issues, we firstly implemented the OpenMP to Nek5000 mini-app, Nekbone. It uses Jacobi-preconditioned conjugate gradients and the gather-scatter operation, which are principal computation and communication kernels in Nek5000. Consequently, Nekbone is used as kernel benchmarks for Nek5000.
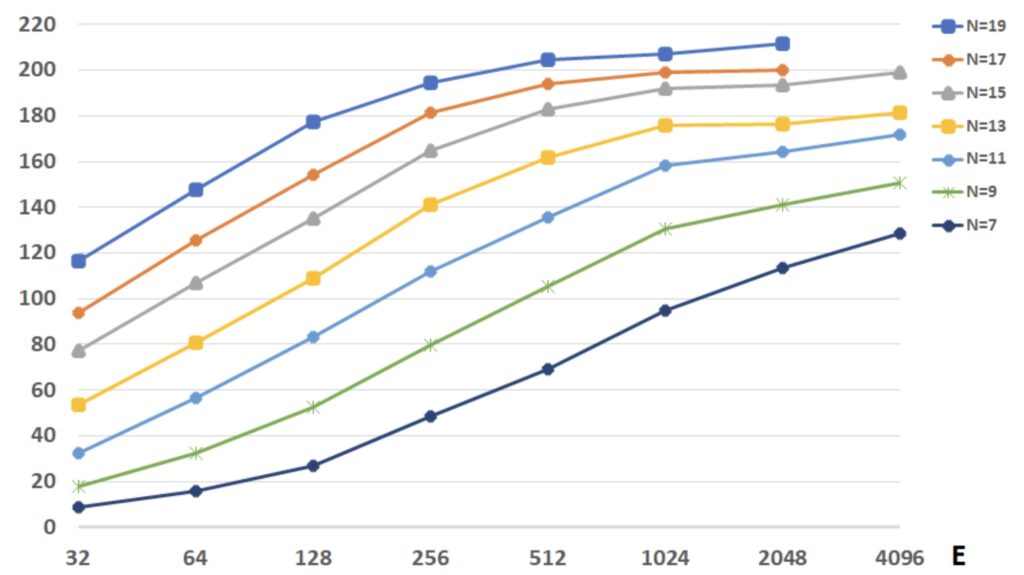
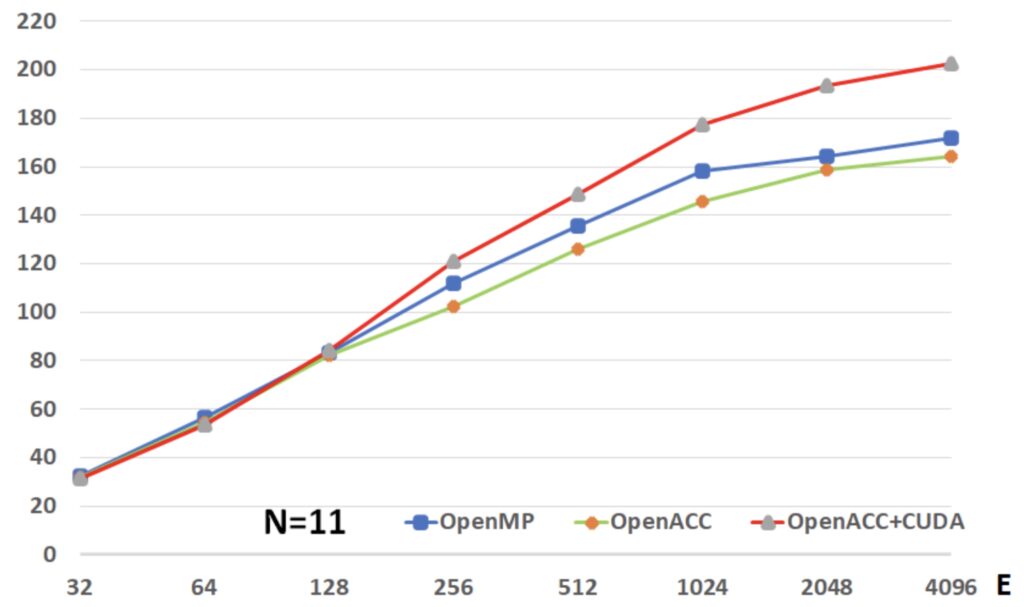
We used a 3D eddy problem to verify and validate Nek5000 simulations on GPU systems. To run 100,000 steps, the maximum errors (by comparing with exact solutions) between CPU version and OpenACC are O(10^-12) for the velocity fields and O(10^-8) for the pressure field.
For more information on NEK5000 visit: https://nek5000.mcs.anl.gov
References:
[2] OpenMP: www.openmp.org




