
HPC applications have always had to grapple with running on a wide range of hardware. The current era is no exception, with large contracts awarded around the world to vendors who will provide the bulk of the computational power with accelerator devices. In particular, the LUMI machine in Finland (https://www.lumi-supercomputer.eu/lumi_supercomputer/) is one of several being built by HPE/Cray based on AMD CPUs and AMD GPUs. AMD GPUs have not been a feature of the HPC landscape in the last decade (since Tianhe-1 https://en.wikipedia.org/wiki/Tianhe-1), despite being well known in consumer space, so this is a welcome change to make the environment more competitive. You can consider how best to port your code to LUMI at https://enccs.github.io/port-to-lumi/#/. In this article, we’ll talk about the motivations of the GROMACS development team in reaching its decision in the hope that other research codes approaching similar crossroads might find it useful to learn from our experiences.

GROMACS is one of the worlds most widely used HPC codes. It is written in C++17 and is nearly unique in being able to run well on almost all known hardware. That is the result of the development teams’ focus on performance and portability, but it has come at a high cost. We adopted CUDA (https://developer.nvidia.com/cuda-zone) in the early days of general-purpose GPU computing and have been very happy with our ongoing collaboration with Nvidia developers to extend the capabilities. An OpenCL port (https://www.khronos.org/opencl/) was contributed to GROMACS by Stream HPC (https://streamhpc.com/) back in 2015, which has been working well ever since. Our primary motivation in accepting and maintaining the contribution was as a pragmatic investment into portability via using a vendor-independent programming model. We hoped it might become the primary means to extend support to new platforms. It did prove useful on AMD and Intel iGPU devices. Over time, the GROMACS team extended it to support PME also, but given the dearth of HPC GPUs from vendors other than Nvidia, the user base didn’t justify as much support as with CUDA. On Nvidia devices, the performance we achieved with OpenCL was never quite as good as with CUDA, either. We gradually evolved a performance-portability layer within GROMACS to permit force-schedule code to be implemented regardless of the GPU configuration supported in the build. The strong similarity between CUDA and OpenCL meant that the portability layer was not overly onerous to maintain and extend, but trying to take advantage of strengths of both languages required some fancy footwork in C++ and with the preprocessor. Having to write the OpenCL kernels in C (while supporting OpenCL 1.2) was a burden for GROMACS. OpenCL is a good option for projects wishing to take advantage of JIT compilation, or avoid C++, and not needing interoperability with e.g. AMD’s ROCm libraries.
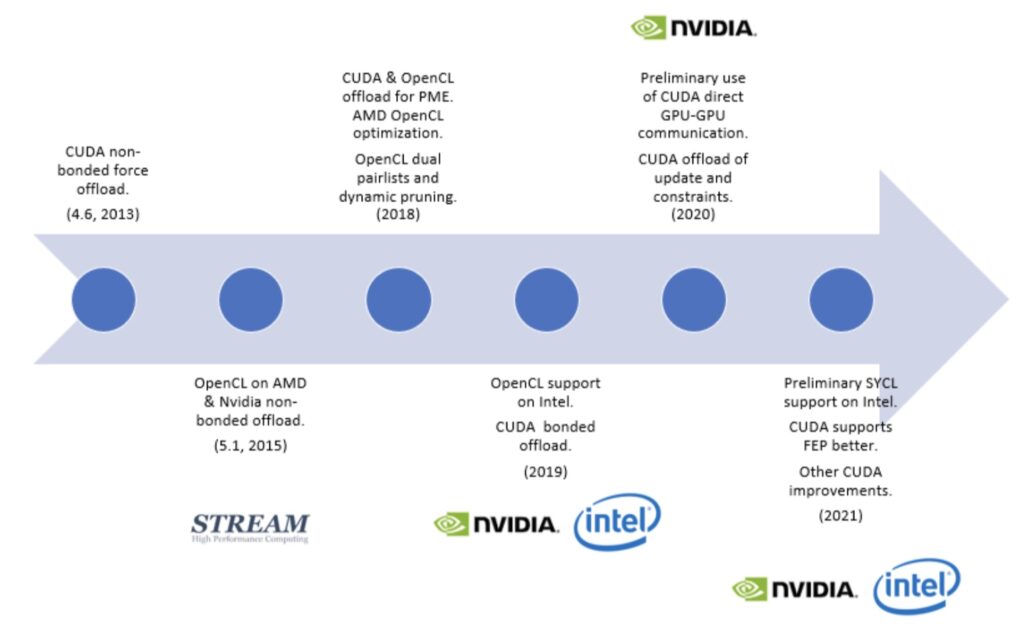
Intel has been very keen to build on the existence of the GROMACS OpenCL port as they positioned their entry to the HPC GPU market, which is still a year or more off. In the meantime, their oneAPI framework for HPC development (https://software.intel.com/content/www/us/en/develop/tools/oneapi.html) includes DPC++, an implementation of SYCL. SYCL (https://www.khronos.org/sycl/) is an open standard supported by multiple vendors and your code can run today on many kinds of devices, including GPUs from AMD, Intel, or Nvidia. Intel established a Center of Excellence at the KTH University in Stockholm which funds Dr. Andrey Alekseenko to port GROMACS to SYCL to run on Intel’s GPUs. Andrey’s early experiences with the language have been fruitful. Some important capabilities were available in the GROMACS 2021 release, although Intel’s HPC devices are still in development. When adopting SYCL for Intel GPUs, we aimed to replace OpenCL as our vendor-neutral standard language for portable parallelism. Of course, in practice achieving portability requires developing against more than one implementation of the standard, or at least multiple backends supported by that implementation, so we already planned to support another SYCL implementation running on other devices as a portability check of the code written for Intel’s DPC++.
AMD provides its own language like CUDA, called HIP as part of the ROCm framework (https://rocmdocs.amd.com/en/latest/). HIP code is standard C++ which is extremely similar to CUDA. AMD provides high-quality tools to automatically convert CUDA code to HIP. Once in HIP, the code can be compiled by AMD’s HIP-clang (based on https://clang.llvm.org/) to run on AMD GPUs or via source-to-source translation to compile with nvcc for Nvidia devices. Maintaining both CUDA and HIP is a lot of work, so one recommended approach is that you then keep the converted code in HIP. This has the further advantage of being simply standard C++ code (albeit requiring a special compiler). That will suit a lot of projects, particularly if portability to Intel devices is not a concern. Do note that while the CUDA feature set supported by HIP is not complete, almost all CUDA code will convert to HIP successfully. AMD kindly provided to the GROMACS development team hip-ified versions of recent GROMACS releases, which we were able to study and learn from in considering our choice.
The GROMACS development team faced a difficult choice. We already had an OpenCL port, however, many GROMACS features were not yet implemented in it. Writing OpenCL code is quite low level and laborious, while being OK to maintain alongside structurally similar CUDA code. A HIP port would run fast and be easy to produce, but would orphan many development branches based on CUDA and alienate the valuable contributions from Nvidia developers. We did not want to give up our CUDA port now, and nor did we want to duplicate thousands of lines of CUDA to HIP and have to maintain the same code in OpenCL, CUDA, SYCL, *and* HIP. We did a trial of doing the hip-ification of our CUDA code at configuration time, which worked reasonably well, but was quite complicated.
It was attractive to consider using SYCL in GROMACS also for AMD GPUs, since there was already effort underway in GROMACS in that direction targeting Intel GPUs. The hipSYCL (https://github.com/illuhad/hipSYCL) open-source project run at Heidelberg University already supported CPUs, as well as Nvidia and AMD GPUs in SYCL by extending existing clang toolchains, and was also funded by Intel to support the recent SYCL 2020 standard. We already wanted to use hipSYCL as our portability check of the DPC++ code for Intel GPUs. We built a working relationship with the hipSYCL team led by Aksel Alpay. Based on Andrey’s work and Aksel’s advice, we were able to test the performance of a GROMACS hipSYCL port running the short-range non-bonded kernels on Mi50 GPUs. AMD’s HIP port was roughly twice as fast in that comparison at this early stage, but we thought that was promising enough to adopt hipSYCL as the supported platform for GROMACS on machines like LUMI. It is important to realize that, since hipSYCL is designed to extend existing clang toolchains, it can be used in conjunction with AMD’s production HIP compiler for code generation. As such, there is no inherent reason for a slowdown of SYCL code compiled with hipSYCL compared to HIP code, and we expect that these performance differences will vanish with increasing maturity of hipSYCL and the SYCL port, and once potential differences between the SYCL model and the HIP model have been accounted for. Microbenchmark comparisons of SYCL with other languages have been decent (https://dl.acm.org/doi/10.1145/3388333.3388643 and https://sycl.tech/research/). At a very late stage in our decision process, we learned also that the US Department of Energy is funding development to support SYCL for AMD GPUs in Intel’s DPC++ compiler (https://www.hpcwire.com/off-the-wire/argonne-ornl-award-codeplay-contract-to-strengthen-sycl-support-for-amd-gpus/). So the future of SYCL on AMD GPUs looks promising.
A key factor here is that the GROMACS team does not have the resources in the long term to maintain a CPU-only port, as well as ones for OpenCL, CUDA, SYCL, and perhaps something else. To help with this, we have deprecated the OpenCL support, but not yet removed it because it functions as a safety net while SYCL support is being implemented. We never seriously considered C++ performance portability frameworks like Kokkos (https://kokkos.org/) or Raja (https://github.com/LLNL/RAJA), because SYCL was already adopted in order to get support for Intel GPUs. It will be necessary for GROMACS developers to customize parts of the SYCL code for the vagaries of compilers and devices. However, the fact remains that the different SYCL ports are all one standard language. That offers us hope that in the future we can spend our time porting new features to SYCL and optimizing existing ones, rather than wrestling with writing, maintaining, and extending our own GROMACS-specific GPU portability layers. The opportunity cost for GROMACS users from the need to do that work to maintain performance portability is quite high. Over a multi-year timespan, we expect GROMACS users will benefit enough from the side effects of adopting SYCL also for AMD GPUs that it will offset any theoretical loss of performance from not using a vendor-specific language.
We’re looking forward to an interesting and exciting future with multiple vendors’ accelerators supported by the same language, and we hope GROMACS users will enjoy the new capabilities.
Article written by Dr. Mark Abraham of ENCCS with advice from Dr. Szilárd Páll of KTH. Together with Dr. Andrey Alekseenko of KTH and Dr. Artem Zhmurov of ENCCS they are producing the hipSYCL port of GROMACS.
For more information on GROMACS visit: http://www.gromacs.org.




