
The following report has been composed by Pawel Herman (KTH), Anders Lansner (KTH), Naresh Balaji Ravichandran (KTH), Jing Gong (ENCCS) and Artem Zhmurov (ENCCS)
In the Computational Brain Science Lab [1] at KTH Royal Institute of Technology, the research group is led by professors Pawel Herman and Anders Lanser. The research concerns brain simulation and brain-like computing and uses publicly available simulation tools as well as their own simulators and data analysis tools.
Since the autumn of 2021, ENCCS started a collaboration with this lab to accelerate their BCPNNSim code on heterogeneous systems. The algorithmic innovation used in the code we call structural plasticity (Ravichandran et al. 2020) was developed a couple of years ago and enables this entire project by producing benchmark results on par with multi-layer perceptrons running error back-propagation and other standard approaches like Restricted Bolzmann Machines and Autoencoders. We compare runs of BCPNN on several standard ML benchmarks like MNIST, Fashion-MNIST, CIFAR-10, SVHN, and Ember (malware detection, interrupt vector data) with own runs and literature data on performance of other ML algorithms (Ravichandran et al. 2021). Performance is on par with human performance, but slightly lower than the most complex and optimized supervised approaches, which however achieve super-human performance. Other potential benefits of the BCPNN solution are its unsupervised learning, prototype extraction, robustness to data distortion, “one-shot learning”, and incremental learning capabilities, e.g. learning from streaming data, and its relative simplicity and hardware friendliness (Ravichandran et al. 2022). It can further rather easily be converted to spiking communication which is useful for e.g. HPC scaling as well as neuromorphic computing.
Within the project, we have successfully ported the code to NVIDIA GPUs using OpenACC. The code was carefully profiled and analyzed using NVIDIA Nsight tools. One of the immediate optimizations that were performed based on this analysis was to introduce asynchronous OpenACC calls. We also did some additional optimization to the CUDA version, which at this point is not fully ported to the GPU and slightly underperforms when compared to OpenACC. To be able to target AMD GPUs in the future, we created an initial version of the code with OpenMP GPU offloading. We also tested the specific libraries, cuBlas, and cuSparse, with the OpenACC API. They proved to be useful for the code and will probably be used in future versions.
This new GPU-based program (OpenACC) is about 4-5 times faster than the previous MPI-based program on the benchmark runs. We are currently developing a version in CUDA and planning to include support for running complex network models on GPU clusters. In addition, it is rather easy to convert the code from CUDA to HIP and enable running on AMD GPU clusters e.g., Dardel at PDC and LUMI at CSC.
The code development for GPUs and benchmarking tests have been performed on the EuroHPC supercomputer Vega at IZUM [2]. As an example, the following Figure shows the scalability of the GPU-accelerated code. We scaled Hh (number of hypercolumn modules) while fixing the size of each module, i.e. number of minicolumn per hypercolumn with Mh=100. We compared the running time between the older MPI implementation tested on a Cray XC40 system (Beskow at KTH), OpenACC (Nvidia A100, Vega GPU), and CUDA (Nvidia A100, Vega GPU). The number of cores in the MPI implementation scales by number of hypercolumns, Hh, i.e. we used 30-MPI ranks for Hh=30. We observed a speed-up of 35x compared to the previous MPI implementation.
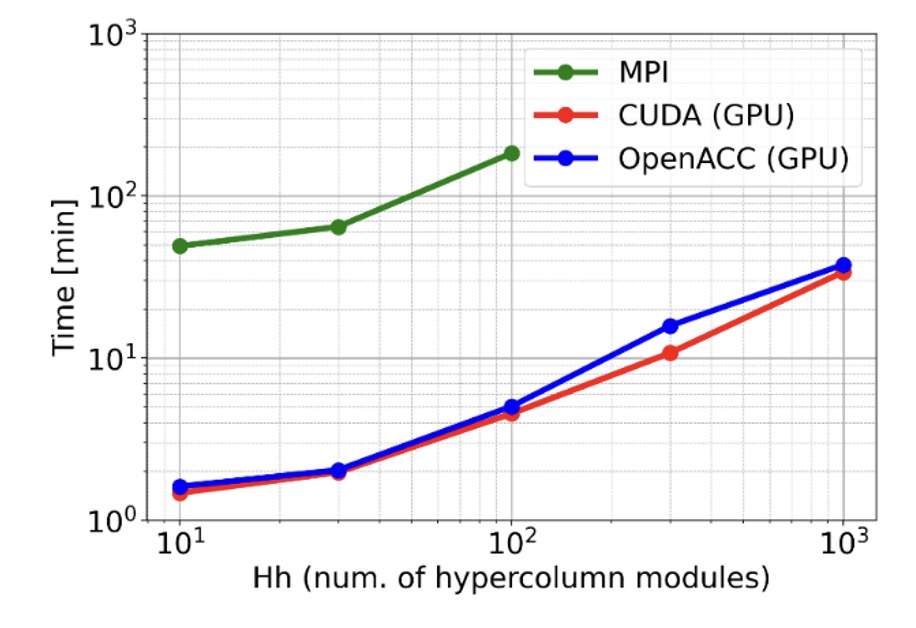
In conclusion, our approach accelerates the development of novel neural models for large-scale machine learning while operating on brain-like computing principles. The project make it possible to run large-scale BCPNN networks on modern HPC architectures.
References:
[1] The Computational Brain Science Lab, https://www.kth.se/cs/cst/research/computational-brain-science-1.779076
[2] HPC Vega, https://doc.vega.izum.si/
Ravichandran, N. B., Lansner, A., & Herman, P. (2020). Learning representations in Bayesian Confidence Propagation neural networks. Proceedings of the International Joint Conference on Neural Networks. https://doi.org/10.1109/IJCNN48605.2020.9207061
Ravichandran, N. B., Lansner, A., & Herman, P. (2022). Brain-like combination of feedforward and recurrent network components achieves prototype extraction and robust pattern recognition. ArXiv Preprint. https://doi.org/10.48550/arxiv.2206.15036
Ravichandran, N. B., Lansner, A., & Herman, P. (2021). Brain-Like Approaches to Unsupervised Learning of Hidden Representations - A Comparative Study. Artificial Neural Networks and Machine Learning – ICANN 2021, LNCS, 162–173. https://doi.org/10.1007/978-3-030-86383-8_13




