
SMHI is awarded 10.000 GPU node hours on LUMI using the EuroHPC JU Development Call!
The Swedish Meteorological and Hydrological Institute (SMHI) is an expert authority with a global perspective and a vital task of predicting changes in weather, water and climate. The institute is a hub for applied research, providing forecasts, warnings and support for decision making – all based on science, advanced technology and large quantities of weather- and climate-data.
Technical/scientific Challenge
Nearly all meteorological agencies in the world, including SMHI, possesses troves of archival data of observations spanning decades in paper format. The ambition of the project is to optimize and train a sufficiently accurate machine learning model which can handle different forms of tabular data, convert handwritten-text and produce machine-readable files (Figure 1). This would aid and accelerate the digitization work from the paper archives into data, which is done manually as of now. As a result of the project, SMHI aims at digitizing numerous historical weather observations that will help a better understanding of climate, especially of the occurrence of extreme weather events.
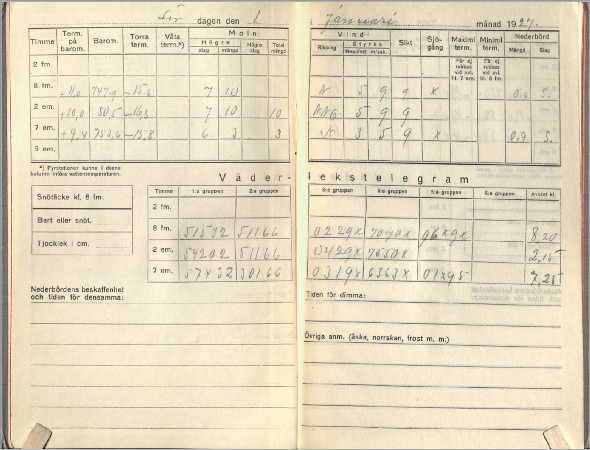
Figure 1: Example of two pages from a scanned weather journal dated 1st January 1927.
Proposed solution
Dawsonia is a table-detection and handwritten text recognition (HTR) project aimed at data-rescue of old weather journals. It specializes in digitization of handwritten numeric data in the form of tables. Unlike simple optical character recognition (OCR) of printed prose, we are also interested in the structural layout of the text in tables and digitizing the handwritten text within them (Figure 2). SMHI aims to use a combination of image processing and machine learning to achieve this. The digitization pipeline (Figure 3) is implemented in Python, using well-known open-source scientific libraries such as scikit-image and TensorFlow.

Figure 2: Tables detected from the scan of Figure 1.
The allocation at LUMI enables the team to optimize a pipeline for the digitization. Here, an optimal complexity for the different tasks (table-detection and HTR) within the pipeline will be required. Expanding the training dataset and discovering the optimal model parameters will involve several training and evaluation cycles for which GPUs are beneficial.

Figure 3: Digitization pipeline
Business impact
The code and the project, although young, has attracted interest both externally, from meteorology agencies abroad, and internally, from SMHI from groups dealing with paper documents in tabular format. If successful it can accelerate the process of digitization from many such archives.
Benefits
An HPC allocation enables us to rapidly test and develop the product. For example, in the current version of the code, the handwritten text recognition (HTR) neural network has been tested on both a CPU cluster of 8 cores and a GPU in LUMI.
- On the CPU the neural network training takes 11 hours.
- On the GPU the whole training takes only 1 hour.
A GPU at disposal allows for faster tuning hyperparameters of this model. Alternatively to use other openly available neural networks also requires some extra training (also known as transfer learning) where GPUs are handy.
Information was provided my Ashwin Mohanan, Scientific programmer at SMHI.




